





La cartographie cérébrale, qui consiste à associer des régions du cerveau à différents traits, comme des maladies, des fonctions cognitives ou des comportements, est un champ de recherche majeur des neurosciences. Cette approche, qui se base sur des modèles statistiques, fait face à de nombreux biais. Pour essayer d’y contrevenir, des chercheurs de l’équipe ARAMIS, conjointe entre l’Institut du Cerveau et Inria, et leurs collaborateurs à l’Université du Queensland (Australie) et à Westlake University (Chine), proposent un nouveau modèle statistique pour traiter ces données. Les résultats sont publiés dans le Journal of Medical Imaging.
Cartographier le cerveau
La cartographie du cerveau est un défi qui mobilise de nombreux chercheurs en neuroscience dans le monde. Un objectif central de cette approche est d’identifier des associations entre certains régions du cerveau et différents traits, comme des pathologies, des scores cognitifs, ou des comportements. Un terme plus technique pour ce type d’étude est « Brain-wide association study » ou étude d’association à l’échelle du cerveau entier. La démarche dans ces études est de tester massivement des régions du cerveau pour identifier celles qui sont associées à un trait d’intérêt.
« La difficulté est que nous cherchons un peu une aiguille dans une botte de foin, sauf que l’on ne sait pas combien il y a d’aiguilles, ou dans notre cas, combien de régions cérébrales nous devons trouver », explique Baptiste Couvy-Duchesne (Inria), premier auteur de l’étude.
Relever les défis de la redondance des signaux
Un premier défi réside dans le nombre de mesures cérébrales disponibles par individus, qui peut rapidement atteindre le million dans ce type d’étude. De plus, les régions du cerveau sont corrélées entre elles. Certaines régions sont très connectées et associées à beaucoup d’autres, comme les nœuds d’un réseau. D’autres en revanche sont plus isolées, soit par leur indépendance vis-à-vis des autres régions cérébrales, soit par leur contribution très spécifique à un trait ou une fonction cognitive.
« Si une région du cerveau associée à notre trait d’intérêt fait partie d’un réseau très connecté, l’analyse du signal va avoir tendance à détecter tout le réseau, car celui-ci se propage au sein de régions corrélées entre elles », poursuit le chercheur.
Ce signal, qui peut sembler très fort à première vue, est en réalité très redondant. Comment trouver alors, au sein du réseau associé au trait d’intérêt, la ou les régions qui contribuent réellement ?
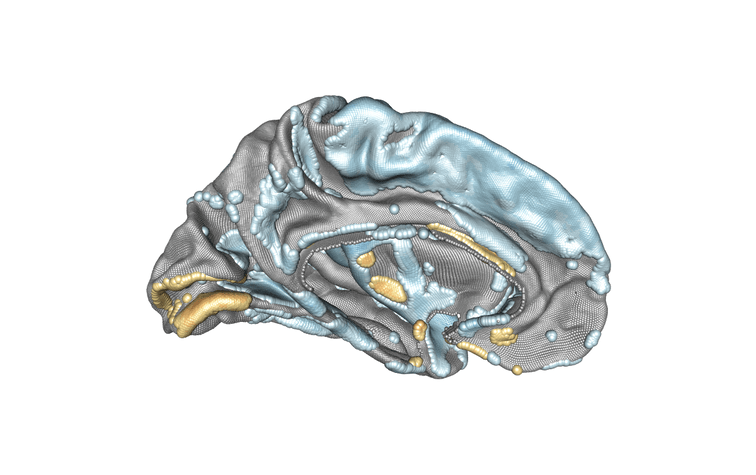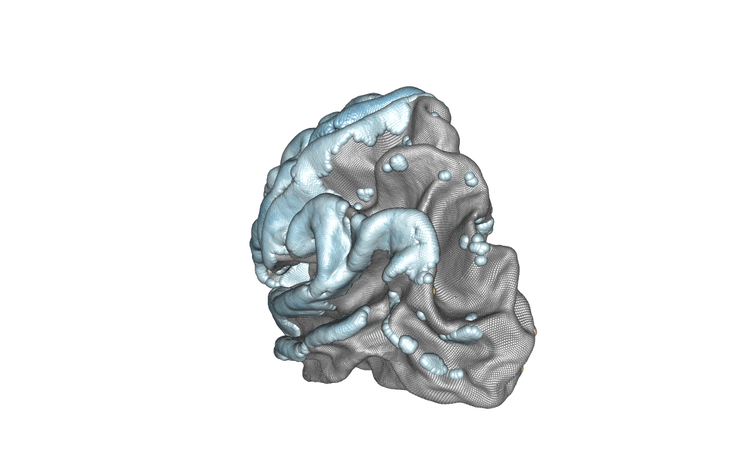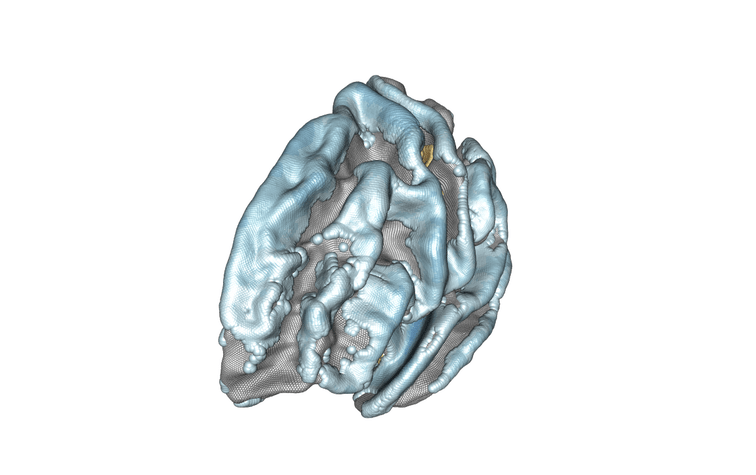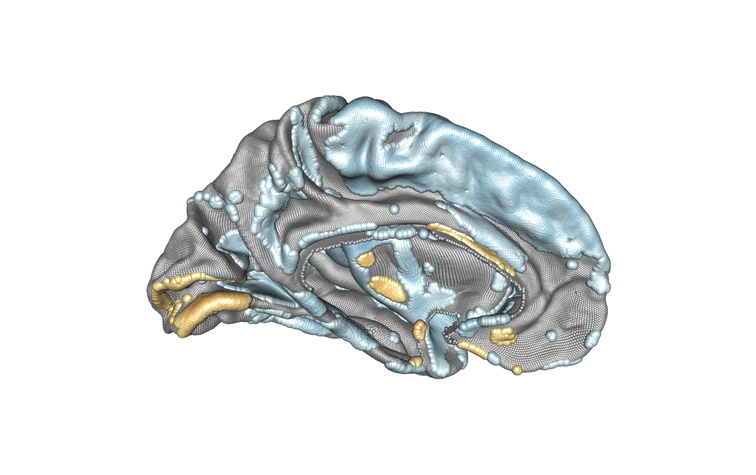
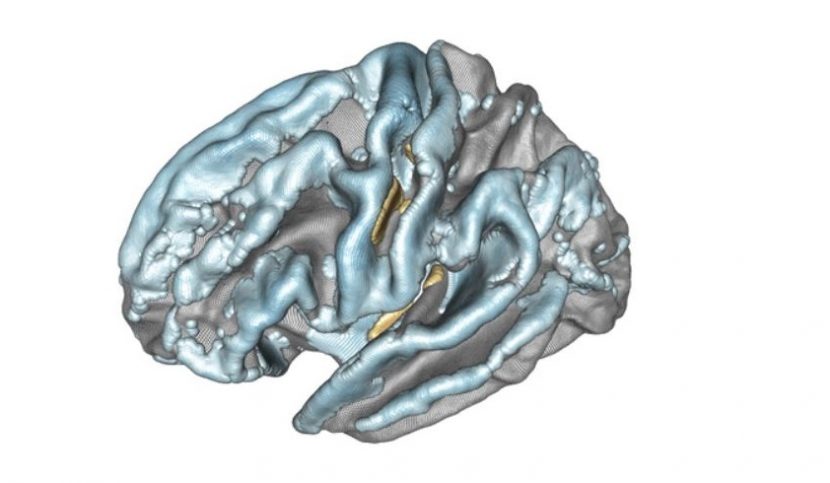
Modélisation de l’hémisphère gauche du cerveau et de l’association entre l’âge des sujets et l’épaisseur corticale. Les régions associées positivement sont en jaune/orange/rouge, celles associées négativement sont en bleu. Crédit : Inria/Baptiste Couvy-Duchesne
Pour résoudre ce problème, les chercheurs proposent de nouvelles méthodes statistiques, à la fois adaptées à la grande dimension et à modéliser la structure de corrélation complexe au sein de l’image.
Des simulations pour développer de nouvelles méthodes statistiques
Afin de tester les méthodes statistiques développées, les chercheurs ont besoin de données très contrôlées.
« On ne peut pas faire de tests directement avec de véritables traits ou maladies, puisqu’on ne sait pas ce que l’on est censé trouver » précise Baptiste Couvy-Duchesne (Inria) « une méthode pourrait ainsi trouver 10 régions associées à un trait, une autre 20, sans que l’on sache laquelle a raison. »
La clé de ce problème se trouve dans la réalisation de ce qu’on appelle des simulations. Les chercheurs utilisent de véritables imageries cérébrales, mais étudient de fausses maladies ou de faux scores, qu’ils ont construits pour être associés à des dizaines ou des centaines de régions prédéfinies du cerveau. Ainsi, ils sont par exemple capables de vérifier si la méthode statistique qu’ils ont développée détecte bien les régions attendues, mais également si elle en détecte d’autres (« faux positifs »).
Une méthode plus robuste et questions en suspens
Une fois leur méthode calibrée grâce à ces simulations, qui ont aussi permises de montrer que leur approche était plus précise que celles déjà existantes, les chercheurs ont utilisé des traits réels comme validation.
« Notre nouvelle méthode trouve en moyenne moins de régions, parce qu’elle parvient à faire abstraction des associations redondantes. La prochaine étape est de l’appliquer dans la maladie d’Alzheimer », conclut le chercheur.
Un aspect particulièrement mis en évidence par l’équipe de chercheurs est l’importance de la redondance que laissent passer les méthodes statistiques actuelles. De nombreuses associations faites aujourd’hui pourraient s’avérer peu solides ou pertinentes. De nombreux facteurs difficiles à contrôler peuvent jouer sur la qualité des IRM comme les mouvements de la tête ou le type de machines utilisées et peuvent conduire de fausses associations. Au-delà du développement de méthodes d’analyse plus fines, l’enjeu de la qualité et de l’homogénéité des données semble crucial.
Source
Baptiste Couvy-Duchesne, Futao Zhang, Kathryn E. Kemper, Julia Sidorenko, Naomi R. Wray, Peter M. Visscher, Olivier Colliot, Jian Yang, « A parsimonious model for mass-univariate vertex-wise analysis, » J. Med. Imag 9(5), 052404 (2022), doi: 10.1117/1.JMI.9.5.052404.